Ejercicio 1
¿Cuál de las siguientes estructuras es un diccionario con todos los valores asociados a sus claves de tipo str Y todas sus claves de tipo tupla?
Ejercicio 2
¿Con qué valor se debe actualizar la variable i para que el programa permita cargar tres (3) días de marzo distintos?
fechas=[]
i=0
while i<5:
try:
dia=int(input('Ingrese un día de marzo (Ej: 15): '))
if dia in range(1,32) and dia not in fechas:
fechas.append(dia)
i+= … # Completar
else:
print('Día inválido o repetido')
except ValueError:
print('Debe ser un número entero')
print(fechas)Ejercicio 3
¿Qué contenido tendrá la lista equiposCba?
def sonCba(x):
resp='**'
if x[1]=='Cba' or 'Córdoba' in x[0]:
resp=x[1][:3].upper()+'-'+x[0]
return resp
equipos=[['Central Córdoba','Sgo','Ferroviario'],
['Talleres','Cba','Tallarines'],
['Instituto','Cba','Gloria'],
['Estudiantes','BsAS','Pincharrata'],
['Rosario Central','Ros','Canallas'],
['Belgrano','Cba','Celeste']]
equiposCba=list(map(sonCba,equipos))Ejercicio 4
¿Cuál de las sentencias propuestas va en el código utilizado para confeccionar el siguiente gráfico?
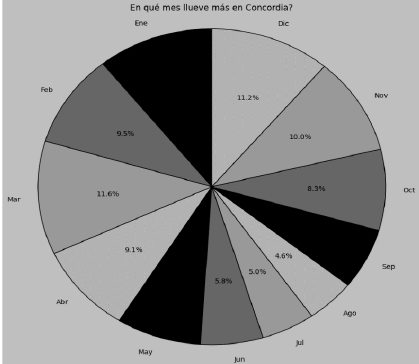
Seleccioná la opción correcta:
Ejercicio 5
Dado el siguiente DataFrame examenes:
Alumno Parcial 1 Parcial 2 Carrera TP
0 Manuel 10.0 9.0 Industrial 9.0
1 Ana NaN NaN Petróleo 10.0
2 Francisco NaN 8.0 Petróleo 9.0
3 Ema 2.0 8.0 Química 6.0
4 Luis 5.0 7.0 Industrial NaN¿Qué sentencia genera la siguiente salida?
3 Química
Ejercicio 6
Dados los siguientes archivos:
Palermo.txt, contiene:
etiquetas;2;cajas
cartucheras minnie;7;unidadesUrquiza.txt, contiene:
anotador rayado chico;17;unidades
lapicera bic azul;11;cajas
lapicera bic roja;3;cajas¿Qué contendrá el archivo Urquiza.txt al terminar la ejecución del siguiente programa?
suc011=open('Palermo.txt')
lineas=suc011.readlines()
suc011.close()
for i in range(len(lineas)):
campos=lineas[i].split(';')
lineas[i]=' '.join(campos)
suc405=open('Urquiza.txt')
for lin in suc405:
lineas.append(lin)
suc405.close()
suc011=open('Palermo.txt','w')
for lin in lineas:
suc011.write(lin)
suc011.close()Nota:
split()genera una lista con las partes de un string separadas por el argumento. Ej:txt='1-2-3'→txt.split('-')→['1','2','3']join()permite armar un texto concatenando los elementos de una lista, separados por la cadena a la que se aplica. Ej:lista=['ana','ema','luis']→'-'.join(lista)→'ana-ema-luis'
Ejercicio 7
Si se espera la siguiente salida:
[['Talleres', 'Cba', 'Tallarines'], ['Rosario Central', 'Ros', 'Canallas']]¿Cuál definición de letras() es la correcta para que el siguiente programa la muestre?
equipos=[['Central Córdoba','Sgo','Ferroviario'],
['Talleres','Cba','Tallarines'],
['Instituto','Cba','Gloria'],
['Estudiantes','BsAS','Pincharrata'],
['Rosario Central', 'Ros','Canallas'],
['Belgrano','Cba','Celeste']]
equipSelec=list(filter(letras,equipos))
print(equipSelec)Nota: 'll' es la doble ele (LL en minúsculas).
Ejercicio 8
Dado el siguiente DataFrame examenes:
Alumno Parcial 1 Parcial 2 Carrera TP
0 Manuel 10.0 9.0 Industrial 9.0
1 Ana NaN NaN Petróleo 10.0
2 Francisco NaN 8.0 Petróleo 9.0
3 Ema 2.0 8.0 Química 6.0
4 Luis 5.0 7.0 Industrial NaN¿Qué muestra por pantalla el siguiente print()?
print(examenes.sort_values(by=['TP','Parcial 2'],
ascending=[False, False]))Ejercicio 9
¿Qué contenido queda en deudas?
deudas={'ana':[500,200], 'ema':[1000,2110],
'Luis':[185,25], 'JUAN':[2550]}
for amigo in deudas:
debe=deudas[amigo]
debe.sort()
deudas[amigo]=debeNota: El método sort() ordena una lista de menor a mayor. Ej: a=[11,2,3] → a.sort() → [2,3,11]